Why You Should Optimize Context, Not Prompts
Prompt optimization is the obvious next step after prompt engineering.
If hand-written prompts are brittle, let an optimizer improve them. Let it search over instructions. Let it select examples. Let it compile a better prompt from data and metrics.
This is a reasonable idea. It has produced useful systems. DSPy is a strong representative of this direction: it frames itself as a framework for programming rather than prompting language models, and its optimizers can tune the prompts or LM weights of a DSPy program against a user-specified metric.
But for many agents, prompt optimization is not the most important optimization surface.
The problem is not that prompts do not matter.
The problem is that prompts are often the wrong thing to optimize first.
An agent prompt is not just an instruction. It is a mixture:
prompt =
system_instruction
+ role
+ context_data
+ examples
+ user_instruction
Prompt optimization usually focuses on the instruction-shaped parts of this mixture: the wording, the demonstrations, the phrasing of the task, the examples that surround the call.
But agent behavior often depends more on context_data: retrieved documents,
tool observations, memory records, intermediate state, previous generated
values, summaries, citations, and outputs from other agents.
If the model sees the right evidence, a mediocre instruction often works.
If the model sees the wrong evidence, a beautiful instruction only makes the wrong answer more fluent.
This post is about a different optimization target:
Do not only optimize what you say to the model. Optimize what the model sees.

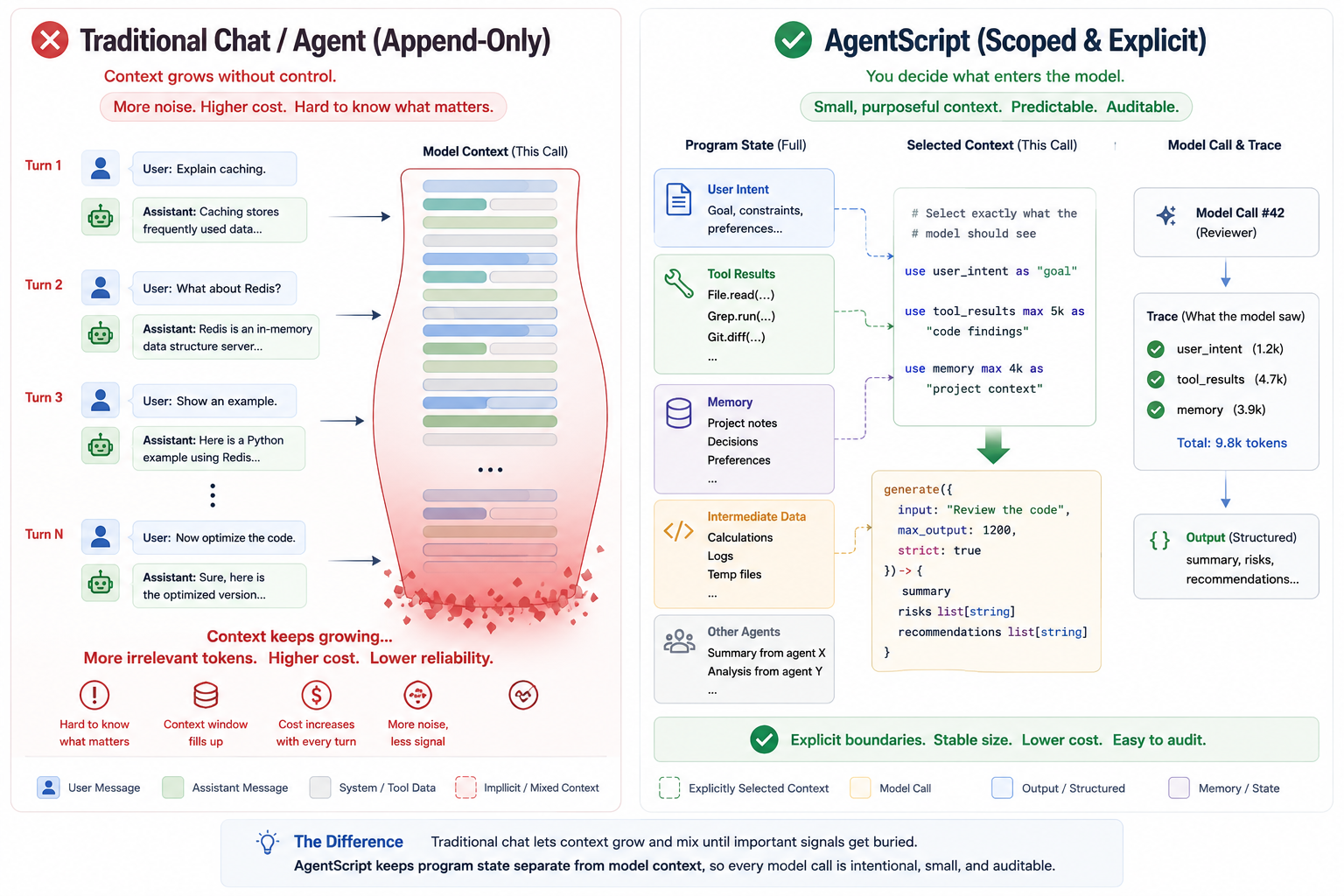
The Prompt Is Not the Unit of an Agent
For a single LLM call, the prompt feels like the obvious unit.
You write an instruction. You provide a few examples. You test the output. You adjust the wording.
That mental model breaks down in agents.
An agent does not just have a prompt. It has a changing context boundary.
A research agent may have:
- the user question
- search queries
- search results
- retrieved documents
- summaries of those documents
- memory records from previous runs
- intermediate observations
- failed attempts
- tool errors
- outputs from helper agents
- final answer requirements
Some of that data should enter the next model call. Some should not.
The failure mode is often not:
The instruction was unclear.
It is:
The model saw the wrong context.
Or:
The right context existed in the program, but it never entered the prompt.
Or:
The context entered the prompt, but in the wrong form.
A tool result might be too large. A memory query might retrieve stale advice. A summary might drop the citation needed by the final answer. A reasoning step may need a compact digest, while the answer step needs source-preserving excerpts.
These are not mainly wording problems.
They are context selection problems.
Prompt Text Is a Soft Optimization Variable
Prompt optimization has an attractive promise: replace manual prompt tweaking with search.
DSPy's MIPROv2, for example, jointly optimizes instructions and few-shot examples. The MIPRO work frames the problem as optimizing free-form instructions and demonstrations for modules in multi-stage LM programs, using downstream metrics without gradients or module-level labels.
That is a serious and useful line of work.
But the optimized object is still soft.
Prompt wording has difficult properties:
high-dimensional
free-form
model-sensitive
hard to constrain
hard to compare semantically
easy to overfit
hard to debug when it works
hard to debug when it fails
A prompt diff can show that some words changed. It rarely explains why the system became more reliable.
Did the model improve because the new instruction is genuinely better?
Because one phrase happens to activate a behavior in this model?
Because a few-shot example resembles the validation set?
Because the optimizer found a local trick that will disappear with the next model version?
Because the downstream metric is incomplete?
These questions are not signs that prompt optimizers are useless. They are signs that free-form prompt text is a difficult optimization surface.
It is too close to model-specific behavior.
It is too far from the actual data-flow problem inside many agents.
Context Is a Better Optimization Surface
Context is different.
Context is not primarily a sentence.
Context is a set of choices.
Should the model see raw tool output or a summary?
Should it see the top three documents or the top ten?
Should it see recent memory, durable lessons, or no memory at all?
Should it see citation-preserving excerpts or compressed observations?
Should a final answer step receive the full evidence bundle, while an earlier planning step only receives a small digest?
These are structured decisions.
They are easier to enumerate:
none
compact digest
summary
top documents
source-preserving excerpts
combined memory + docs
They are easier to inspect:
This run used docs.top5 max 4k.
That run used scratch.digest max 500.
This run omitted memory entirely.
They are easier to trace:
Which context source entered the prompt?
How much token budget did it receive?
Was it clipped?
Was the source URL preserved?
Was this context slot omitted?
They are also more portable across models.
Different models may respond differently to the same phrase. But the question "should the model see the retrieved documents or only a summary?" is less tied to one model's prompt quirks. GPT, Claude, Gemini, Qwen, and local models may differ in style, but they all need the right evidence.
Context optimization is not magic. It can overfit too. A context policy selected on one dataset may fail on another distribution.
But when it fails, the failure is inspectable.
You can see the selected source. You can see what was omitted. You can see whether the model had access to the evidence. You can change a structured choice, not a spell.
From Prompt Engineering to Context Engineering
Prompt engineering asks:
What should I say to the model?
Context engineering asks:
What should the model see?
That shift matters.
In ordinary Python or TypeScript agents, context often appears as strings, message arrays, framework objects, or prompt templates. The boundary between local program data and prompt context is maintained by convention.
AgentScript starts from a stricter rule:
Local data is not prompt context.
Tool results, memory query results, intermediate observations, trace events, and outputs from other agents do not enter the prompt automatically.
If the model should see a value, the program must select it with use.
use input.question as "user question"
use docs.summary max 4k as "evidence"
use past max 2k as "past lessons"
This is the first step.
Context becomes visible.
A use declaration says:
source = docs.summary
label = "evidence"
budget = 4k
It is not just a string template. It is a context contract.
The next step is natural:
If context can be explicit, context alternatives can be explicit too.
use one of: Context Search Space as Code
AgentScript can express a context choice directly:
use one of {
none: empty
compact: scratch.digest max 500
verbose: scratch.summary max 4k
grounded: docs.top5 max 4k selected
} as "evidence"
This says:
There is a context slot named "evidence".
It can be absent.
It can use a compact digest.
It can use a verbose summary.
It can use retrieved documents.
The current selected version is grounded.
This is not runtime magic.
There is no hidden optimizer running inside the agent.
There is no invisible learning state.
There is only a declaration of possible context sources, and a visible selected choice.
use one of declares the search space.
selected records the current specialization.
empty means the context slot is absent.
The model does not see the candidate list. It only sees the selected context source.
If grounded is selected, the prompt receives an evidence section built from
docs.top5.
If none: empty is selected, the prompt receives no evidence section at all.
The source remains auditable.
The runtime remains simple.
Why empty Belongs in the Same Mechanism
It is tempting to invent a separate syntax for optional context.
For example:
use? docs.top5 max 4k as "evidence"
But that makes optionality a separate language mechanism.
A simpler model is to treat absence as one candidate in the same context choice:
use one of {
none: empty
docs: docs.top5 max 4k
} as "evidence"
This is easier to read and easier to optimize.
The search space is explicit:
evidence �∈ { none, docs }
The default is explicit too. If none is first, the unoptimized program omits
the context slot by default. If docs is first, the unoptimized program includes
it by default.
No extra optional-use syntax is needed.
Absence is just another context choice.
selected Is a Source-Level Decision
The important part of this design is where the optimization result lives.
It lives in source code.
use one of {
none: empty
compact: scratch.digest max 500
verbose: scratch.summary max 4k
grounded: docs.top5 max 4k selected
} as "evidence"
The current choice is not hidden in a database.
It is not stored in a runtime profile.
It is not controlled by an ambient optimizer.
It is written next to the alternatives.
This makes the program self-describing.
A human can review it.
A tool can parse it.
A trace can point back to it.
A version control diff can show exactly what changed:
use one of {
none: empty
compact: scratch.digest max 500
- verbose: scratch.summary max 4k selected
- grounded: docs.top5 max 4k
+ verbose: scratch.summary max 4k
+ grounded: docs.top5 max 4k selected
} as "evidence"
This is a very different kind of optimization artifact from a rewritten prompt.
The output is not a new incantation.
The output is a changed context decision.
Optimization as Source-to-Source Specialization
The cleanest optimization model for AgentScript is source-to-source specialization.
An optimizer does not need to mutate the runtime.
It does not need to inject hidden state.
It does not need to rewrite the prompt text.
It can do something much simpler:
read AgentScript source
find use one of sites
evaluate candidates
move the selected marker
write new AgentScript source
The input is AgentScript.
The output is AgentScript.
The runtime still executes ordinary AgentScript.
There are two useful output forms.
The development form keeps the search space:
use one of {
none: empty
compact: scratch.digest max 500
verbose: scratch.summary max 4k
grounded: docs.top5 max 4k selected
} as "evidence"
This form is good for review, auditing, and future optimization.
The production form can be flattened:
use docs.top5 max 4k as "evidence"
If the selected variant is empty, the production form can remove the context
slot entirely:
// evidence omitted
Both forms are understandable.
Neither requires a special runtime learning mechanism.
Runtime Should Be Boring
This is the main design constraint.
The runtime should not be where learning hides.
At runtime, a use one of site resolves to exactly one candidate.
The rule is deterministic:
if a candidate is marked selected:
use that candidate
else:
use the first candidate
Then the selected candidate behaves like ordinary use.
If the candidate is non-empty:
grounded: docs.top5 max 4k selected
the runtime behaves as if the program had written:
use docs.top5 max 4k as "evidence"
If the candidate is empty:
none: empty selected
the runtime behaves as if there were no use for that context slot.
That is all.
No prompt rewriting.
No hidden profile overlay.
No adaptive runtime state.
No agent self-modification during execution.
This keeps the trace honest. When a trace says the model saw docs.top5 max 4k
as evidence, the source code contains the corresponding selected candidate.
Why This Is More Auditable Than Prompt Optimization
Prompt optimization often produces an artifact that looks like text:
You are a careful and precise assistant. Use the provided context...
The optimizer may have improved it, but the result is still hard to inspect as an engineering artifact.
A reviewer sees changed wording.
They may not know what behavior changed.
They may not know whether the improvement will transfer to another model.
A context optimization diff is different.
- verbose: scratch.summary max 4k selected
+ grounded: docs.top5 max 4k selected
This says something concrete:
The model now sees retrieved documents instead of a summary.
Or:
- lessons: Lessons.relevant(input.question) max 1k selected
+ none: empty selected
This says:
The model no longer receives memory in this step.
These are engineering decisions.
They can be reviewed.
They can be traced.
They can be tested.
They can be reverted.
They can be discussed without guessing which phrase happened to work.
Context Optimization Still Needs Evaluation
None of this removes the need for evaluation.
An optimizer still needs a signal.
That signal may come from fixtures, tests, validation output, user feedback, downstream task success, or human review.
Context optimization can still overfit.
A candidate that works on one fixture set may fail elsewhere. A memory policy that improves one workflow may pollute another. A larger evidence bundle may improve factuality but hurt latency and cost.
The difference is not that context optimization is automatically correct.
The difference is that its variables are visible.
When it fails, you can inspect the context choices directly.
When it improves, you can often explain why.
That matters for agents because agents are not just single model calls. They are programs. Programs need reviewable state, explicit boundaries, and understandable changes.
What This Means for AgentScript
AgentScript's first bet was:
Agent context should be code.
That is what use provides.
use input.question as "user question"
use docs.summary max 4k as "evidence"
The next bet is:
Agent context search space should be code too.
That is what use one of provides.
use one of {
none: empty
compact: scratch.digest max 500
verbose: scratch.summary max 4k
grounded: docs.top5 max 4k selected
} as "evidence"
This is the bridge from context engineering to context optimization.
The language does not need to make prompt text adaptive.
It does not need to optimize role descriptions.
It does not need to let agents rewrite their control flow.
It can keep the core model small:
use declares what the model can see
generate declares where the model is called
one of declares context alternatives
selected records the current context choice
empty records deliberate absence
That is enough to make context optimization possible without hiding it in the runtime.
The Real Question
The old prompt engineering question was:
What should I say to the model?
AgentScript's first question was:
What did the model actually see?
Context optimization adds a second question:
What could the model have seen, and why did we choose this version?
That is the difference between prompt optimization and context optimization.
Prompt optimization searches over language.
Context optimization searches over evidence, memory, summaries, tool results, budgets, and absence.
For agents, that is often the more important surface.
Not because prompts do not matter.
Because in real agent programs, the model's next output is usually constrained less by the beauty of the instruction and more by the quality of the information placed in front of it.
Reliable agents need more than better prompts.
They need context choices that are explicit, scoped, auditable, and eventually optimizable.
That is the direction AgentScript is exploring:
Agent context as code.
Context search space as code.
Learning results as code.