模型到底看到了什么?
本文介绍 AgentScript,一门用于构建显式、有作用域、可审计LLM 上下文的小型领域专用语言。
我们这一代很多程序员,最初接触编程时都遵循一套简单模型:输入、处理、输出。
程序接收数据、处理数据、产出结果。这套模型虽然古老,但十分好用,它让程序的边界清晰可见,逻辑易于理解。
而 LLM 智能体(Agent)彻底打破了这套传统范式。
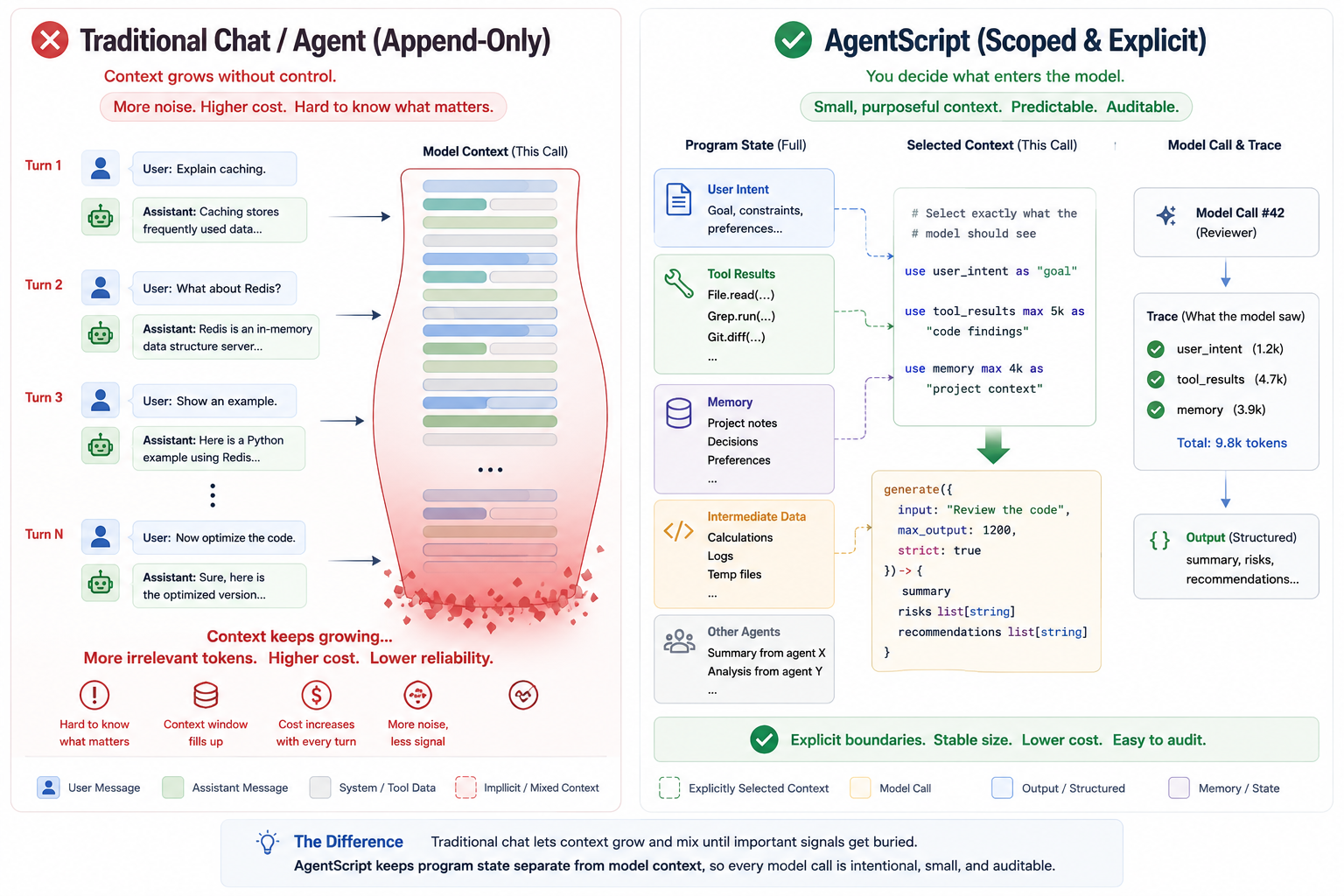
智能体的输入不再只是文件、接口请求、结构化记录,而是复杂的提示词上下文:用户意图、工具返回结果、检索文档、记忆记录、中间状态、重试日志、其他智能体的输出……
输出也不再是简单的返回值,而是一段生成文本或 JSON,必须满足约定格式,才能被后续流程信任与复用。
绝大多数 Agent 项目失败,不是因为调用大模型太难,而是没人能确切知道:模型生成结果前,到底看到了哪些信息。
经过多轮迭代后,Agent 会积累大量局部变量、工具返回、记忆数据、中间观测结果、重试消息、其他智能体输出。一部分数据需要传入下一次模型调用,另一部分则应当隔离。 在绝大多数 Python、TypeScript 实现的 Agent 中,上下文边界全靠开发者的编码习惯维护。
这套方式在小型 Demo 中尚可,但放到真实业务流程里,会变得极度脆弱。
模型到底看到了什么? 哪条工具结果被加入提示词,哪些只是本地临时数据? 记忆是否被截断? 其他智能体的输出,是作为参考证据,还是混入了历史对话? 模型必须输出什么格式,才能进入下一步流转?
AgentScript 的诞生,就是为了让这些问题直接能从代码里找到答案。
AgentScript 是什么
AgentScript 是一门面向 LLM 智能体的小型编程语言,核心目标是让提示词上下文具备显式定义、作用域隔离、类型约束、可追踪、可审计的能力。
它主要面向开发者构建多步骤智能体场景,严格管控工具输出、记忆、中间状态与生成内容。
它不是提示词模板,不是 YAML 配置,也不是通用 Agent 框架。
它的核心理念一句话概括:
智能体上下文,应当由代码显式定义。
语言最核心的两个关键字:use 和 generate。
use content max 8k as "文件内容"
generate({
input: "为忙碌的同事总结这份文件",
max_output: 1000
}) -> {
title
summary
key_points: list[string]
action_items: list[string]
}
use 声明哪些数据可以被模型看到;
generate 定义调用大模型的唯一入口,同时约束输出结构。
在传统输入-处理-输出视角下,AgentScript 直接聚焦 LLM 程序最不稳定的两个边界:提示词输入、生成结果输出。
这门语言真正的价值,不是封装了大模型调用,而是把提示词边界直接暴露在代码层面,一目了然。 语言其余能力:变量、函数、智能体、导入、循环、工具、记忆、执行追踪,全部都是为了支撑这套上下文管控逻辑。
为什么不直接用 Python / TypeScript?
Python、TypeScript 都是优秀的通用编程语言,AgentScript 并非要替代它们。
问题在于:通用语言没有原生的“提示词上下文”概念。 上下文往往以字符串、数组、对象、模板、框架调用、消息列表的形式零散存在。代码逻辑没问题,但上下文意图散落在各处:
const messages = [
system("你是一名审阅者"),
user(`问题:${input.question}`),
user(`搜索结果:${JSON.stringify(results)}`),
user(`历史记忆:${memory.map((item) => item.text).join("\n")}`),
];
const answer = await model.generate(messages);
results 里哪些字段被传入?是否混入了原始工具输出?记忆是否被截断?其他智能体输出是否被作为历史对话?返回结果需要满足什么格式?
这些问题,在通用语言里完全无法显性约束。
而 AgentScript 将上下文选择作为一等公民操作:
use input.question as "用户问题"
use results.summary max 4k as "搜索结果"
use past max 2k as "过往经验"
generate({
input: "仅使用选中的上下文回答",
max_output: 800,
strict: true
}) -> {
answer
citations: list[string]
}
局部变量、工具结果、记忆查询结果、执行追踪,不会自动进入提示词。
只要数据需要被模型看见,就必须通过 use 显式声明。
就这一条规则,彻底改变了智能体的开发方式:提示词不再是字符串拼接的副作用,而是一套有作用域、可契约化的约束。
极简示例:本地文件总结智能体
下面是一个完整的文件总结 AgentScript 程序:
import llm Qwen from "ollama://localhost:11434/qwen3.6"
import tool File from "file://workspace"
main agent FileSummarizer {
model Qwen
role "技术文档撰写人"
description "读取本地文件,生成结构化摘要。"
main func(input { path: string }) {
content = File.read({
path: input.path
})
use input.path as "文件路径"
use content max 8k as "文件内容"
generate({
input: "为忙碌的同事总结这份文件",
max_output: 1000
}) -> {
title
summary
key_points: list[string]
action_items: list[string]
}
}
}
文件工具可以读取工作目录,但工具返回结果不会自动成为提示词上下文。程序手动选择路径与文件内容、打上标签、设置上下文长度上限,再要求模型输出结构化结果。
直接运行:
agentscript run recipes/summarize-file.as --input '{"path":"README.md"}'
使用模拟模型快速验证:
npm install -g @rong/agentscript
agentscript run recipes/summarize-file.as --input '{"path":"README.md"}' --mock --trace
支持多种运行模式:
--mock:使用确定性模拟模型--dry-run:仅构建提示词,不调用模型--trace:输出完整审计日志
执行日志可以清晰展示:选中了哪些上下文、设置了哪些长度限制、哪些内容被截断、使用了什么指令、输出格式要求、校验是否通过。 日志用于调试与审计,本身不会被传入模型。
典型日志示例:
Generate #1
Agent: FileSummarizer / 技术文档撰写人
选中上下文:
[文件路径] input.path
[文件内容] content, 上限=8k, 未截断
指令:
为忙碌的同事总结这份文件
输出结构:
title 字符串
summary 字符串
key_points 字符串列表
action_items 字符串列表
校验: 通过
generate:唯一的模型调用入口
在 AgentScript 中,普通代码可以计算数据、调用��工具、查询记忆、调用其他智能体、维护中间状态。只有 generate 能发起模型调用。
answer = generate({
input: "仅使用选中的上下文回答",
max_output: 800,
attempts: 3,
strict: true
}) -> {
ok: boolean
answer
citations: list[string]
}
-> 后定义输出契约:AgentScript 会强制校验模型返回格式,JSON 异常或结构不匹配时自动重试。下游代码可直接依赖结构化输出,无需手动解析文本。
每一次模型调用都有清晰边界:
- 当前所属智能体身份
- 通过
use选中的上下文 generate内的指令- 可选的输出结构约束
这个边界,就是调试、审计、复盘的最小单元。
作用域 = 上下文边界
AgentScript 依靠代码作用域管控上下文可见性。
use 声明仅对当前作用域、子作用域内后续 generate 生效,不会向上泄漏。函数、智能体调用会创建独立上下文边界。
func caller(input) {
use input.goal as goal
helper(input)
}
func helper(input) {
use input.detail as detail
generate({ input: "基于细节处理" }) -> {
ok: boolean
}
}
helper 内部的模型调用只能看到 input.detail,不会自动继承上层 goal。
跨智能体调用同理:被调用智能体只能看到传入参数与自身 use 声明,不会继承调用方的提示词上下文。
多智能体组合因此更易审计,每个智能体拥有独立上下文契约,而非共享混乱的全局对话缓冲区。
工具返回是数据,不是上下文
AgentScript 最重要的规则之一:工具返回结果是本地程序数据,不会自动进入提示词,必须显式 use 选中。
在代码评审、科研检索、代码分析等场景,工具往往返回大量冗余数据,远超出模型需要的范围。 例如仓库评审场景,可以先收集文件树、TODO 标记、包信息、CI 配置,再只选取必要部分:
use "文件树" 上限=8k
use "TODO发现" 上限=4k
use "包元信息" 上限=4k
use "CI配置" 上限=4k
generate 输出阻碍点、风险、可快速优化项、下一步计划
工具拓展程序能力,use 管控模型可见范围,二者严格区分。
记忆同样显式可控
AgentScript 内置 JSONL、SQLite 两种记忆存储后端,但记忆遵循和工具完全一致的规则: 记忆句柄只是能力,不会自动混入上下文。
import memory Lessons from "file://./.agentscript/lessons.jsonl"
智能体需要先查询记忆,拿到普通数据,再通过 use 手动纳入上下文:
past = Lessons.query({
text: input.goal,
kind: "lesson",
limit: 5
})
use input.goal as goal
use past max 2k as "过往经验"
写入记忆同样显式可控:
Lessons.add({
kind: "lesson",
text: reflection.insight,
goal: input.goal
})
支持反思、自我迭代,同时避免上下文无限膨胀。后续运行可复用历史经验��,但全程可追溯、可管控。
智能体模式:基于基础原语自由组合
AgentScript 不会硬编码 Planner、Executor、反射等特定模式关键字。 ReAct、规划-执行、评估-优化、反思、自我迭代、多智能体协作,全部由一套极简原语组合实现:
- 智能体、函数:划分边界
- 工具:扩展外部能力
- 记忆:持久化状态
use:管控提示词上下文generate:模型调用与输出契约- 执行追踪:可审计
针对并行独立任务,内置 parallel for:
results = parallel for step in plan.steps max 10 {
Executor({
goal: input.goal,
step: step
})
}
并行执行结果仍是本地数据,只有手动 use 后才会进入后续提示词。
use results.summary max 6k as 执行结果
项目现状
AgentScript 仍处于实验阶段,但核心语言设计已稳定落地。
已实现功能:
- 语法解析器、语义校验器
- 模拟运行时
- OpenAI / Anthropic / Ollama 模型适配器
- 文件、环境变量、HTTP、Shell 工具
- JSONL / SQLite 记忆后端
- 结构化输出校验
- 执行追踪
- 基础运算符、赋值、并行循环
- 完整 CLI 命令
可用于实验、示例、本地工作流,1.0 正式版前语法可能微调。
后续规划:稳定中间表示、完善错误提示、VS Code 语法高亮支持。
项目现阶段目标不是做成熟生产级框架,而是验证一个核心理念:
智能体程序最重要的部分,或许不是模型调用的框架封装,而是调用前的上下文契约。
快速上手
安装 CLI:
npm install -g @rong/agentscript
运行示例:
agentscript run recipes/summarize-file.as --input '{"path":"README.md"}'
免安装直接运行:
npx @rong/agentscript run recipes/code-review.as --input '{"path":"src"}'
模拟运行、调试追踪、离线校验,一键即可。
项目地址:
结语
行业里谈论智能体,总离不开工具、记忆、规划、自主性。 但所有能力,都依赖一个最基础的问题: 模型生成下一段输出前,到底看到了什么?
AgentScript 正是围绕这个问题构建。它将提示词上下文变成可声明、可限定、可管控、可校验、可追踪的代码契约。
我们相信:可靠的生产级智能体,需要上下文工程成为编程范式,而非靠编码习惯约束。